Blaflow 中的向量存储组件
向量数据库存储向量数据,支持聊天机器人和检索增强生成(RAG)等 AI 工作负载。
向量数据库组件用于建立与现有向量数据库的连接,或创建内存向量存储,以存储和检索向量数据。
向量数据库组件与记忆组件不同,后者专门用于从外部数据库存储和检索聊天消息。
在流程中使用向量存储组件
本示例使用 Astra DB 向量存储 组件。您的向量存储组件的参数和身份验证可能不同,但文档摄取工作流是相同的。文档从本地机器加载并分块。Astra DB 向量存储使用连接的模型组件生成嵌入,并将其存储在连接的 Astra DB 数据库中。
这些向量数据随后可用于检索增强生成等工作负载。
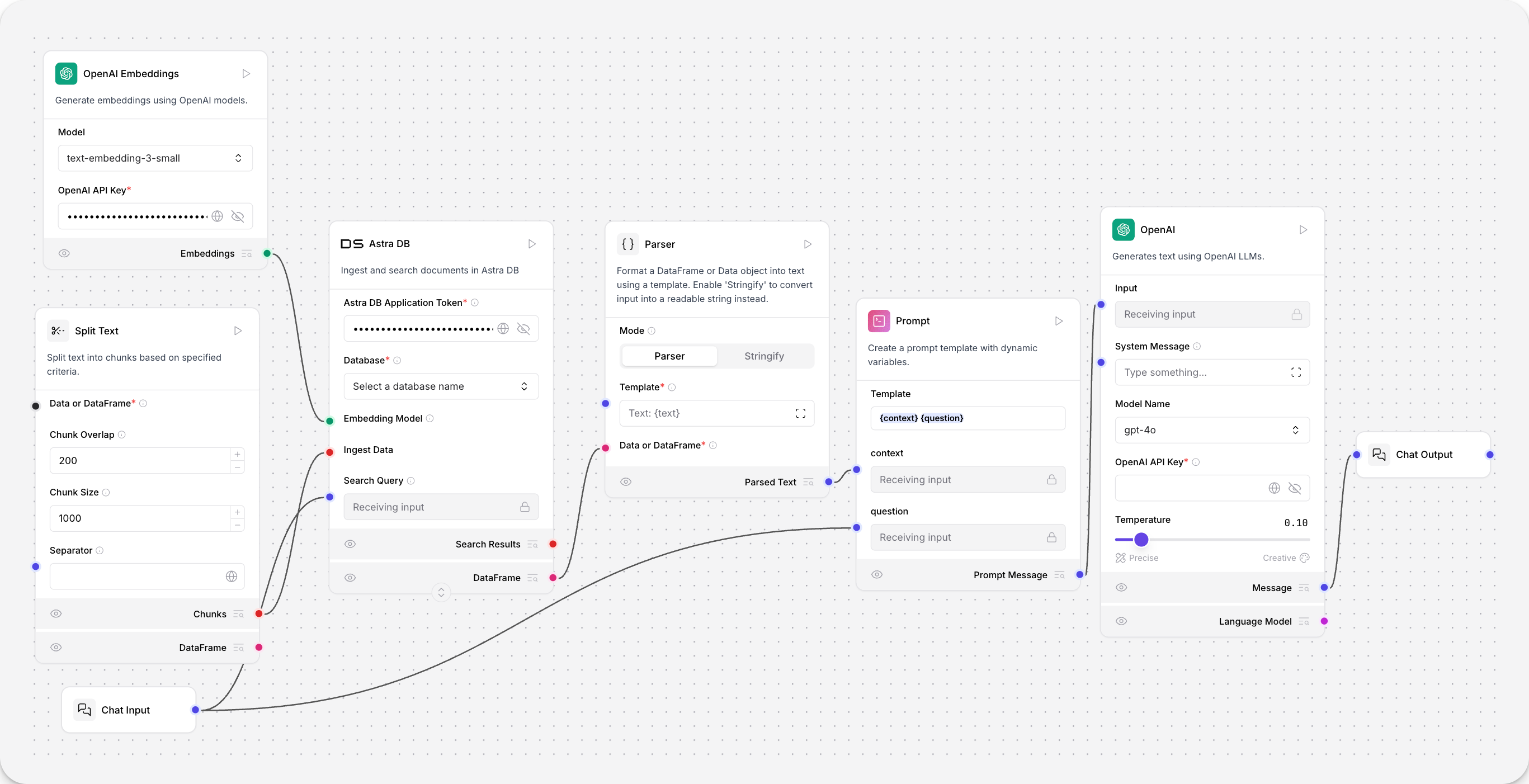
用户的聊天输入被嵌入,并与文档摄取期间嵌入的向量进行相似性搜索比较。
结果从向量数据库组件输出为数据对象,并解析为文本。
此文本填充提示词组件中的 {context} 变量,从而指导 Open AI 模型 组件的响应。
或者,将向量数据库组件的 Retriever 端口连接到检索工具,然后连接到智能体组件。这使智能体能够将��您的向量数据库作为工具使用,并根据可用数据做出决策。
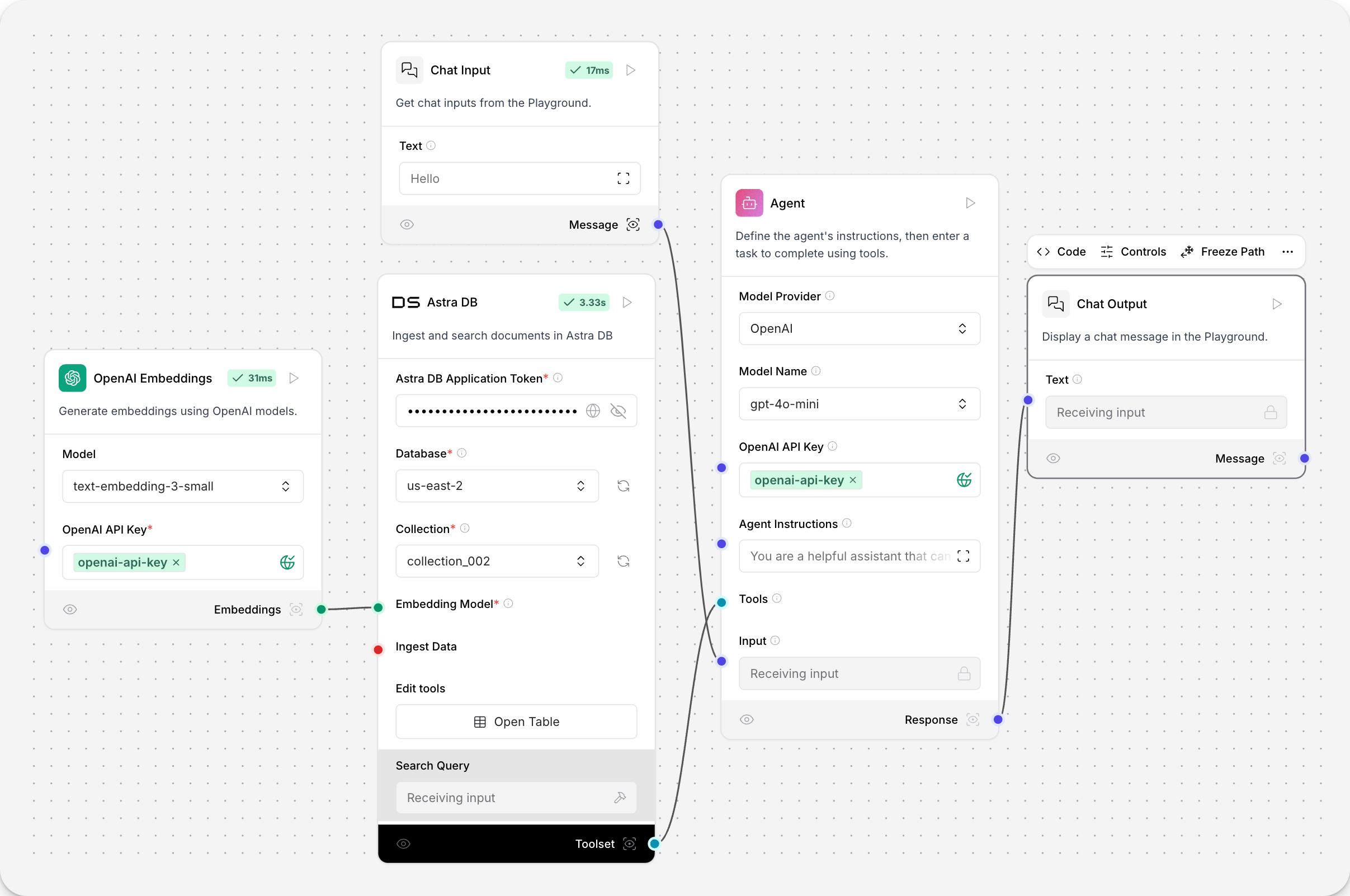
Astra DB 向量存储
此组件使用 Astra DB 实现具有搜索功能的向量存储。
更多信息,请参阅 DataStax 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| token | Astra DB 应用令牌 | 用于访问 Astra DB 的身份验证令牌。 |
| environment | 环境 | Astra DB API 端点的环境。例如,dev 或 prod。 |
| database_name | 数据库 | Astra DB 实例的数据库名称。 |
| api_endpoint | Astra DB API 端点 | Astra DB 实例的 API 端点。此选项会覆盖数据库选择。 |
| collection_name | 集合 | Astra DB 中存储向量的集合名称。 |
| keyspace | 键空间 | Astra DB 中用于集合的可选键空间。 |
| embedding_choice | 嵌入模型或 Astra Vectorize | 选择嵌入模型或使用 Astra vectorize。 |
| embedding_model | 嵌入模型 | 指定嵌入模型。Astra vectorize 集合不需要。 |
| number_of_results | 搜索结果数量 | 返回的��搜索结果数量(默认:4)。 |
| search_type | 搜索类型 | 使用的搜索类型。选项包括 Similarity、Similarity with score threshold 和 MMR (Max Marginal Relevance)。 |
| search_score_threshold | 搜索分数阈值 | 使用 Similarity with score threshold 选项时,搜索结果的最小相似度分数阈值。 |
| advanced_search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典。 |
| autodetect_collection | 自动检测集合 | 确定是否自动检测集合的布尔标志。 |
| content_field | 内容字段 | 用作向量存储文本内容字段的字段。 |
| deletion_field | 基于字段删除 | 提供时,在加载新数据之前,将删除目标集合中元数据字段值与输入元数据字段值匹配的文档。 |
| ignore_invalid_documents | 忽略无效文档 | 确定是否在运行时忽略无效文档的布尔标志。 |
| astradb_vectorstore_kwargs | AstraDBVectorStore 参数 | AstraDBVectorStore 的附加参数的可选字典。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 使用指定参数配置的 Astra DB 向量存储实例。 |
| search_results | 搜索结果 | 相似性搜索结果,作为数据对象列表。 |
生成嵌入
Astra DB 向量存储 组件提供两种生成嵌入的方法。
-
嵌入模型:通过连接 Blaflow 中的嵌入组件使用您自己的嵌入模型。
-
Astra Vectorize:使用 Astra DB 的内置嵌入生成服务。创建新集合时,选择嵌入提供程序和模型,包括 Datastax 托管的 NVIDIA
NV-Embed-QA模型。
嵌入模型选择在创建新集合时进行,之后无法更改。
有关使用 Astra DB 向量存储 组件与嵌入模型的示例,请参阅向量存储 RAG 入门项目。
更多信息,请参阅 Astra DB Serverless 文档。
混合搜索
Astra DB 组件包含默认启用的混合搜索。
与混合搜索相关的组件字段包括 Search Query、Lexical Terms 和 Reranker。
- Search Query 通过向量相似性查找结果。
- Lexical Terms 是逗号分隔�的关键词字符串,如
features, data, attributes, characteristics。 - Reranker 是混合搜索中使用的重排序模型。
重排序模型为
nvidia/llama-3.2-nv.reranker。
混合搜索执行向量相似性搜索和词汇搜索,比较两种搜索结果,然后返回整体最相关的结果。
要在 Astra DB 组件中使用混合搜索,请按以下步骤操作:
- 点击 New Flow > RAG > Hybrid Search RAG。
- 在 OpenAI 模型组件中,添加您的 OpenAI API 密钥。
- 在 Astra DB 向量存储组件中,添加您的 Astra DB 应用令牌。
- 在 Database 字段中,选择您的数据库。
- 在 Collection 字段中,选择要搜索的集合。 创建集合时必须启用混合搜索支持。
- 在试运行中,输入关于数据的问题,例如
What are the features of my data?您的查询将发送到两个组件:OpenAI 模型组件和 Astra DB 向量数据库组件。 OpenAI 组件包含一个提示,用于从您的输入创建词汇查询:
_10You are a database query planner that takes a user's requests, and then converts to a search against the subject matter in question._10You should convert the query into:_101. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams._102. A question to use as the basis for a QA embedding engine._10Avoid common keywords associated with the user's subject matter.
- 要查看 OpenAI 组件从您的集合生成的关键词和问题,请在 OpenAI 组件中点击 。
_101. Keywords: features, data, attributes, characteristics_102. Question: What characteristics can be identified in my data?
-
要查看从 OpenAI 组件响应生成的DataFrame,请在结构化输��出组件中点击 。 DataFrame 传递给解析器组件,该组件将 Keywords 列的内容解析为字符串。
此逗号分隔的单词字符串传递给 Astra DB 组件的 Lexical Terms 端口。 注意,Astra DB 端口的 Search Query 端口连接到步骤 6 中的 聊天输入 组件。 此 Search Query 被向量化,Search Query 和 Lexical Terms 内容都发送到
find_and_rerank端点的重排序器。重排序器将向量搜索结果与词汇搜索的术语字符串进行比较。 混合搜索的最高排名结果将返回给 试运行。
更多信息,请参阅 DataStax 文档。
AstraDB 图向量存储
此组件使用 AstraDB 实现具有图功能的向量存储。 更多信息,请参阅 Astra DB Serverless 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| collection_name | 集合名称 | AstraDB 中存储向量的集合名称(必需) |
| token | Astra DB 应用令牌 | 用于访问 AstraDB 的身份验证令牌(必需) |
| api_endpoint | API 端点 | AstraDB 服务的 API 端点 URL(必需) |
| search_input | 搜索输入 | 相似性搜索的查询字符串 |
| ingest_data | 摄取数据 | 要摄取到向量存储的数据 |
| namespace | 命名空间 | AstraDB 中用于集合的可选命名空间 |
| embedding | 嵌入模型 | 使用的嵌入模型 |
| metric | 度量 | 向量比较的距离度量(选项:"cosine"、"euclidean"、"dot_product") |
| setup_mode | 设置模式 | 向量存储的配置模式(选项:"Sync"、"Async"、"Off") |
| pre_delete_collection | 预删除集合 | 确定是否在创建新集合前删除集合的布尔标志 |
| number_of_results | 结果数量 | 相似性搜索返回的结果数量(默认:4) |
| search_type | 搜索类型 | 使用的搜索类型(选项:"Similarity"、"Graph Traversal"、"Hybrid") |
| traversal_depth | 遍历深度 | 图遍历搜索的最大深度(默认:1) |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最小相似度分数阈值 |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 使用指定参数配置的 Astra DB 图向量存储实例。 |
| search_results | 搜索结果 | 相似性搜索结果,作为 数据 对象列表。 |
Cassandra
此组件创建具有搜索功能的 Cassandra 向量存储。 更多信息,请参阅 Cassandra 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| database_ref | 字符串 | 数据库的联系点或 AstraDB 数据库 ID |
| username | 字符串 | 数据库的用户名(AstraDB 留空) |
| token | SecretString | 数据库的用户密码或 AstraDB 令牌 |
| keyspace | 字符串 | 表键空间或 AstraDB 命名空间 |
| table_name | 字符串 | 表或 AstraDB 集合的名称 |
| ttl_seconds | 整数 | 添加文本的生存时间 |
| batch_size | 整数 | 单批处理的数据数量 |
| setup_mode | 字符串 | Cassandra 表的配置模式 |
| cluster_kwargs | 字典 | Cassandra 集群的附加关键字参数 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量 |
| search_type | 字符串 | 执行的搜索类型 |
| search_score_threshold | 浮点数 | 搜索结果的最小相似度分数 |
| search_filter | 字典 | 搜索查询的元数据过滤器 |
| body_search | 字符串 | 文档文本搜索词 |
| enable_body_search | 布尔值 | 启用正文搜索的标志 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Cassandra | 使用指定参数配置的 Cassandra 向量存储实例。 |
| search_results | List[数据] | 相似性搜索结果,作为 数据 对象列表。 |
Cassandra 图向量存储
此组件实现具有搜索功能的 Cassandra 图向量存储。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| database_ref | 联系点 / Astra 数据库 ID | 数据库的联系点或 AstraDB 数据库 ID(必需) |
| username | 用户名 | 数据库的用户名(AstraDB 留空) |
| token | 密码 / AstraDB 令牌 | 数据库的用户密码或 AstraDB 令牌(必需) |
| keyspace | 键空间 | 表键空间或 AstraDB 命名空间(必需) |
| table_name | 表名 | 存储向量的表或 AstraDB 集合的名称(必需) |
| setup_mode | 设置模式 | Cassandra 表的配置模式(选项:"Sync"、"Off",默认:"Sync") |
| cluster_kwargs | 集群参数 | Cassandra 集群的附加关键字参数的可选字典 |
| search_query | 搜索查询 | 相似性搜索的查询字符串 |
| ingest_data | 摄取数据 | 要摄取到向量存储的数据(数据 对象列表) |
| embedding | 嵌入 | 使用的嵌入模型 |
| number_of_results | 结果数量 | 相似性搜索返回的结果数量(默认:4) |
| search_type | 搜索类型 | 使用的搜索类型(选项:"Traversal"、"MMR traversal"、"Similarity"、"Similarity with score threshold"、"MMR (Max Marginal Relevance)",默认:"Traversal") |
| depth | 遍历深度 | 要遍历的边的最大深度(用于 "Traversal" 或 "MMR traversal" 搜索类型,默认:1) |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最小相似度分数阈值(用于 "Similarity with score threshold" 搜索类型) |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 使用指定参数配置的 Cassandra 图向量存储实例。 |
| search_results | 搜索结果 | 相似性搜索结果,作为 数据 对象列表。 |
Chroma DB
此组件创建具有搜索功能的 Chroma 向量存储。 更多信息,请参阅 Chroma 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Chroma 集合的名称。默认:"blaflow"。 |
| persist_directory | 字符串 | 持久化 Chroma 数据库的目录。 |
| search_query | 字符串 | 在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储的数据(数据 对象列表)。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| chroma_server_cors_allow_origins | 字符串 | Chroma 服务器的 CORS 允许源。 |
| chroma_server_host | 字符串 | Chroma 服务器的主机。 |
| chroma_server_http_port | 整数 | Chroma 服务器的 HTTP 端口。 |
| chroma_server_grpc_port | 整数 | Chroma 服务器的 gRPC 端口。 |
| chroma_server_ssl_enabled | 布尔值 | 启用 Chroma 服务器的 SSL。 |
| allow_duplicates | 布尔值 | 允许向量存储中的�重复文档。 |
| search_type | 字符串 | 执行的搜索类型:"Similarity" 或 "MMR"。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认:10。 |
| limit | 整数 | 当"允许重复"为 False 时,限制比较的记录数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Chroma | Chroma 向量存储实例 |
| search_results | 数据列表 | 相似性搜索结果 |
Clickhouse
该组件实现具有搜索功能的 Clickhouse 向量存储。 更多信息,请参阅 Clickhouse 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| host | 主机名 | Clickhouse 服务器主机名(必需,默认:"localhost") |
| port | 端口 | Clickhouse 服务器端口(必需,默认:8123) |
| database | 数据库 | Clickhouse 数据库名称(必需) |
| table | 表名 | Clickhouse 表名(必需) |
| username | ClickHouse 用户名 | 用于身份验证的用户名(必需) |
| password | 用户密码 | 用于身份验证的密码(必需) |
| index_type | 索引类型 | 索引类型(选项:"annoy"、"vector_similarity",默认:"annoy") |
| metric | 距离度量 | 计算距离的度量(选项:"angular"、"euclidean"、"manhattan"、"hamming"、"dot",默认:"angular") |
| secure | 使用 https/TLS | 覆盖从接口或端口参数推断的值(默认:false) |
| index_param | 索引参数 | 索引参数(默认:"'L2Distance',100") |
| index_query_params | 索引查询参数 | 额外的索引查询参数 |
| search_query | 搜索查询 | 相似性搜索的查询字符串 |
| ingest_data | 摄取数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 要使用的嵌入模型 |
| number_of_results | 结果数量 | 相似性搜索返回的结果数量(默认:4) |
| score_threshold | 分数阈值 | 相似性分数的阈值 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 构建的 Clickhouse 向量存储 |
| search_results | 搜索结果 | 相似性搜索结果,作为 数据 对象列表 |
Couchbase
该组件创建具有搜索功能的 Couchbase 向量存储。 更多信息,请参阅 Couchbase 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| couchbase_connection_string | SecretString | Couchbase 集群连接字符串(必需)。 |
| couchbase_username | 字符串 | Couchbase 用户名(必需)。 |
| couchbase_password | SecretString | Couchbase 密码(必需)。 |
| bucket_name | 字符串 | Couchbase 存储桶名称(必需)。 |
| scope_name | 字符串 | Couchbase 作用域名称(必需)。 |
| collection_name | 字符串 | Couchbase 集合名称(必需)。 |
| index_name | 字符串 | Couchbase 索引名称(必需)。 |
| search_query | 字符串 | 在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储的数据(数据 对象列表)。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认:4(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | CouchbaseVectorStore | 使用指定参数配置的 Couchbase 向量存储实例。 |
Elasticsearch
该组件创建具有搜索功能的 Elasticsearch 向量存储。 更多信息,请参阅 Elasticsearch 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| es_url | 字符串 | Elasticsearch 服务器 URL |
| es_user | 字符串 | Elasticsearch 身份验证用户名 |
| es_password | SecretString | Elasticsearch 身份验证密码 |
| index_name | 字符串 | Elasticsearch 索引名称 |
| strategy | 字符串 | 向量搜索策略("approximate_k_nearest_neighbors" 或 "script_scoring") |
| distance_strategy | 字符串 | 距离计算策略("COSINE"、"EUCLIDEAN_DISTANCE"、"DOT_PRODUCT") |
| search_query | 字符串 | 相似性搜索查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 要使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量(默认:4) |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | ElasticsearchStore | Elasticsearch 向量存储实例 |
| search_results | 数据列表 | 相似性搜索结果 |
FAISS
该组件创建具有搜索功能的 FAISS 向量存储。 更多信息,请参阅 FAISS 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_name | 字符串 | FAISS 索引的名称。默认:"blaflow_index"。 |
| persist_directory | 字符串 | 保存 FAISS 索引的路径。相对于 Blaflow 运行位置。 |
| search_query | 字符串 | 在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储的数据(数据 对象或文档列表)。 |
| allow_dangerous_deserialization | 布尔值 | 设置为 True 以允许从不受信任的来源加载 pickle 文件。默认:True(高级)。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认:4(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | FAISS | 使用指定参数配置的 FAISS 向量存储实例。 |
Graph RAG
该组件在向量存储中执行 Graph RAG(检索增强生成)遍历,实现基于图的文档检索。 更多信息,请参阅 Graph RAG 文档。
示例流程请参考 Graph RAG 模板。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_model | 嵌入模型 | 指定嵌入模型。对于使用 Astra vectorize 嵌入的集合,此参数不是必需的。 |
| vector_store | 向量存储连接 | 向量存储的连接。 |
| edge_definition | 边定义 | 图遍历的边定义。更多信息请参阅 GraphRAG 文档。 |
| strategy | 遍历策略 | 用于图遍历的策略。策略选项从可用策略中动态加载。 |
| search_query | 搜索查询 | 在向量存储中搜索的查询。 |
| graphrag_strategy_kwargs | 策略参数 | 检索策略的额外参数字典(可选)。更多信息请参阅策略文档。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | 数据列表 | 基于图的文档检索结果,作为数据 对象列表。 |
超融合数据库
此组件使用 HCD 实现向量存储。
要使用 HCD 向量存储,请添加您的部署的集合名称、用户名、密码和 HCD 数据 API 端点。
端点必须格式化为 http[s]://**DOMAIN_NAME** 或 **IP_ADDRESS**[:port],例如,http://192.0.2.250:8181。
将 DOMAIN_NAME 或 IP_ADDRESS 替换为您的 HCD 数据 API 连接的域名或 IP 地址。
要将 HCD 向量存储用于嵌入摄取,请将其连接到嵌入模型和文件加载器:
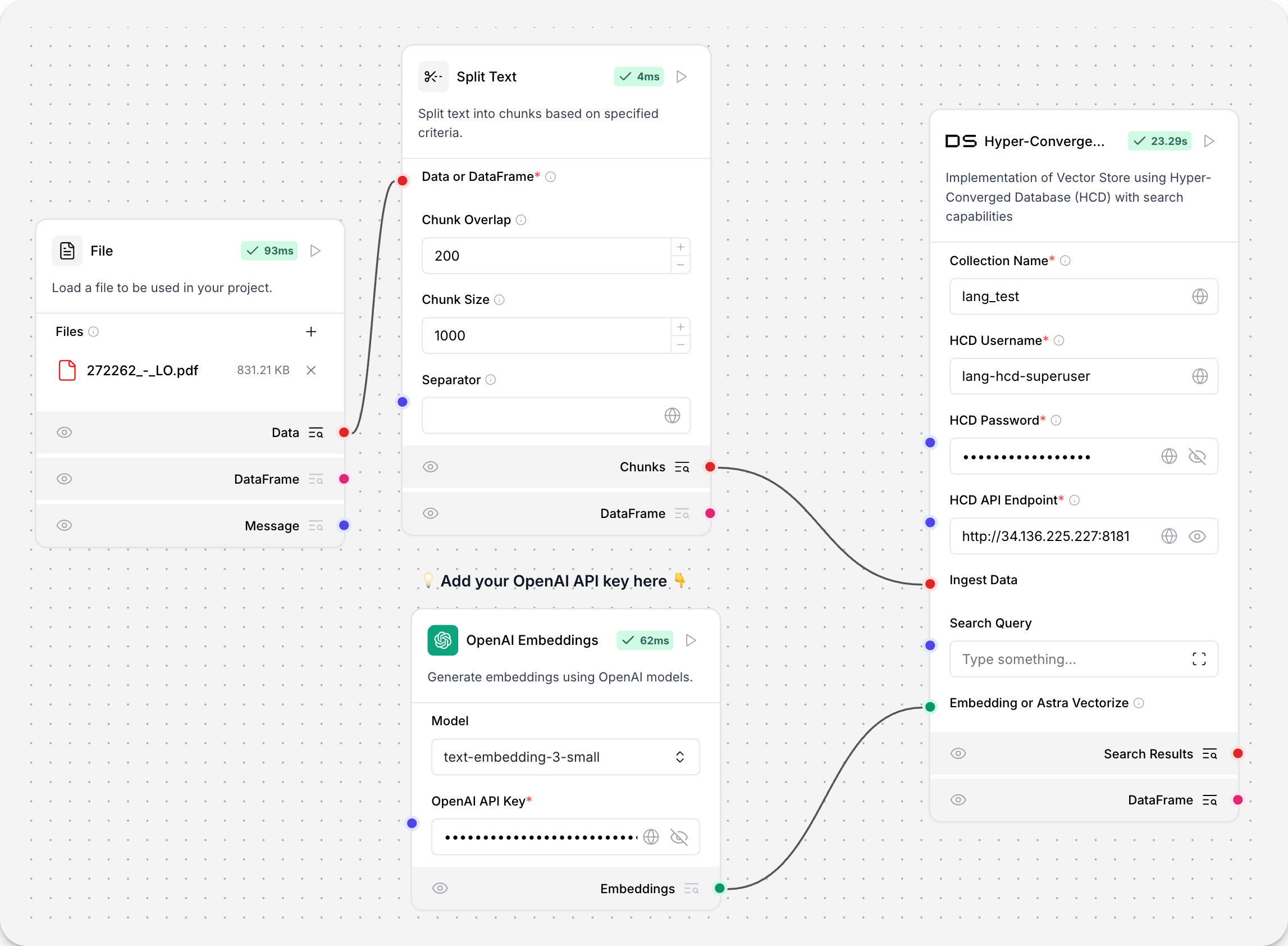
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| collection_name | 集合名称 | HCD 中存储向量的集合名称(必需) |
| username | HCD 用户名 | 用于访问 HCD 的身份验证用户名(默认:"hcd-superuser",必需) |
| password | HCD 密码 | 用于访问 HCD 的身份验证密码(必需) |
| api_endpoint | HCD API 端点 | HCD 服务的 API 端点 URL(必需) |
| search_input | 搜索输入 | 相似性搜索的查询字符串 |
| ingest_data | 摄取数据 | 要摄取到向量存储的数据 |
| namespace | 命名空间 | HCD 中用于集合的可选命名空间(默认:"default_namespace") |
| ca_certificate | CA 证书 | 用于 HCD TLS 连接的可选 CA 证书 |
| metric | 距离度量 | 向量比较的可选距离度量(选项:"cosine"、"dot_product"、"euclidean") |
| batch_size | 批处理大小 | 单批处理数据的可选数量 |
| bulk_insert_batch_concurrency | 批量插入并发数 | 批量插入操作的可选并发级别 |
| bulk_insert_overwrite_concurrency | 批量覆盖插入并发数 | 覆盖现有数据的批量插入操作的可选并发级别 |
| bulk_delete_concurrency | 批量删除并发数 | 批量删除操作的可选并发级别 |
| setup_mode | 设置模式 | 向量存储的配置模式(选项:"Sync"、"Async"、"Off",默认:"Sync") |
| pre_delete_collection | 预删除集合 | 确定是否在创建新集合前删除集合的布尔标志 |
| metadata_indexing_include | 元数据索引包含 | 要包含在索引中的元数据字段的可选列表 |
| embedding | 嵌入向量或 Astra Vectorize | 允许嵌入模型或 Astra Vectorize 配置 |
| metadata_indexing_exclude | 元数据索引排除 | 要从索引中排除的元数据字段的可选列表 |
| collection_indexing_policy | 集合索引策略 | 定义集合索引策略的可选字典 |
| number_of_results | 结果数量 | 相似性搜索返回的结果数量(默认:4) |
| search_type | 搜索类型 | 使用的搜索类型(选项:"Similarity"、"Similarity with score threshold"、"MMR (Max Marginal Relevance)",默认:"Similarity") |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最小相似度分数阈值(默认:0) |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 HCD 向量存储实例。相似性搜索结果作为 数据 对象列表。 |
| search_results | 搜索结果 | 相似性搜索结果作为 数据 对象列表。 |
Milvus
此组件创建具有搜索功能的 Milvus 向量存储。 更多信息,请参阅 Milvus 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Milvus 集合的名称 |
| collection_description | 字符串 | Milvus 集合的描述 |
| uri | 字符串 | Milvus 的连接 URI |
| password | SecretString | Milvus 的密码 |
| username | SecretString | Milvus 的用户名 |
| batch_size | 整数 | 单批处理的数据数量 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量 |
| search_type | 字符串 | 执行的搜索类型 |
| search_score_threshold | 浮点数 | 搜索结果的最小相似度分数 |
| search_filter | 字典 | 搜索查询的元数据过滤器 |
| setup_mode | 字符串 | 向量存储的配置模式 |
| vector_dimensions | 整数 | 向量的维度数量 |
| pre_delete_collection | 布尔值 | 是否在创建新集合前删除集合 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Milvus | 使用指定参数配置的 Milvus 向量存储实例。 |
MongoDB Atlas
此组件创建具有搜索功能的 MongoDB Atlas 向量存储。 更多信息,请参阅 MongoDB Atlas 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| mongodb_atlas_cluster_uri | SecretString | MongoDB Atlas 集群的连接 URI(必需) |
| enable_mtls | 布尔值 | 启用相互 TLS 身份验证(默认:false) |
| mongodb_atlas_client_cert | SecretString | 用于 mTLS 身份验证的客户端证书和私钥组合(如果启用 mTLS 则必需) |
| db_name | 字符串 | 要使用的数据库名称(必需) |
| collection_name | 字符串 | 要使用的集合名称(必需) |
| index_name | 字符串 | Atlas Search 索引的名称,应该是向量搜索(必需) |
| insert_mode | 字符串 | 如何将新文档插入集合(选项:"append"、"overwrite",默认:"append") |
| embedding | 嵌入 | 要使用的嵌入模型 |
| number_of_results | 整数 | 相似性搜索返回的结果数量(默认:4) |
| index_field | 字符串 | 要索引的字段(默认:"embedding") |
| filter_field | 字符串 | 用于过滤索引的字段 |
| number_dimensions | 整数 | 嵌入上下文长度(默认:1536) |
| similarity | 字符串 | 用于测量向量之间相似性的方法(选项:"cosine"、"euclidean"、"dotProduct",默认:"cosine") |
| quantization | 字符串 | 量化通过将 32 位浮点数转换为较小的数据类型来减少内存成本(选项:"scalar"、"binary") |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | MongoDBAtlasVectorSearch | MongoDB Atlas 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Opensearch
此组件创建具有搜索功能的 Opensearch 向量存储 更多信息,请参阅 Opensearch 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| opensearch_url | 字符串 | OpenSearch 集群的 URL(例如 https://192.168.1.1:9200) |
| index_name | 字符串 | 向量将存储在 OpenSearch 集群中的索引名称 |
| search_input | 字符串 | 输入搜索查询。留空以检索所有文档或如果使用混合搜索 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| search_type | 字符串 | 有效值为 "similarity"、"similarity_score_threshold"、"mmr" |
| number_of_results | 整数 | 搜索返回的结果数量 |
| search_score_threshold | 浮点数 | 搜索结果的最小相似度分数阈值 |
| username | 字符串 | OpenSearch 集群的用户名 |
| password | SecretString | OpenSearch 集群的密码 |
| use_ssl | 布尔值 | 使用 SSL |
| verify_certs | 布尔值 | 验证证书 |
| hybrid_search_query | 字符串 | 以 JSON 格式提供自定义混合搜索查询。这允许您结合向量相似性和关键词匹配 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | OpenSearchVectorSearch | OpenSearch 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
PGVector
此组件创建具有搜索功能的 PGVector 向量存储。 更多信息,请参阅 PGVector 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| pg_server_url | SecretString | PostgreSQL 服务器连接字符串 |
| collection_name | 字符串 | 向量存储的表名 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索�返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | PGVector | PGVector 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Pinecone
此组件创建具有搜索功能的 Pinecone 向量存储。 更多信息,请参阅 Pinecone 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_name | 字符串 | Pinecone 索引的名称 |
| namespace | 字符串 | 索引的命名空间 |
| distance_strategy | 字符串 | 计算向量之间距离的策略 |
| pinecone_api_key | SecretString | Pinecone 的 API 密钥 |
| text_key | 字符串 | 记录中用作文本的键 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Pinecone | Pinecone 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Qdrant
此组件创建具有搜索功能的 Qdrant 向量存储。 更多信息,请参阅 Qdrant 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Qdrant 集合的名称 |
| host | 字符串 | Qdrant 服务器主机 |
| port | 整数 | Qdrant 服务器端口 |
| grpc_port | 整数 | Qdrant gRPC 端口 |
| api_key | SecretString | Qdrant 的 API 密钥 |
| prefix | 字符串 | Qdrant 的前缀 |
| timeout | 整数 | Qdrant 操作的超时时间 |
| path | 字符串 | Qdrant 的路径 |
| url | 字符串 | Qdrant 的 URL |
| distance_func | 字符串 | 向量相似性的距离函数 |
| content_payload_key | 字符串 | 内容载荷的键 |
| metadata_payload_key | 字符串 | 元数据载荷的键 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数��据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Qdrant | Qdrant 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Redis
此组件创建具有搜索功能的 Redis 向量存储。 更多信息,请参阅 Redis 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| redis_server_url | SecretString | Redis 服务器连接字符串 |
| redis_index_name | 字符串 | Redis 索引的名称 |
| code | 字符串 | Redis 的自定义代码(高级) |
| schema | 字符串 | Redis 索引的模式 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| number_of_results | 整数 | 搜索返回的结果数量 |
| embedding | 嵌入 | 使用的嵌入函数 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Redis | Redis 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Supabase
此组件创建与具有搜索功能的 Supabase 向量存储的连接。 更多信息,请参阅 Supabase 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| supabase_url | 字符串 | Supabase 实例的 URL |
| supabase_service_key | SecretString | Supabase 身份验证的服务密钥 |
| table_name | 字符串 | Supabase 中表的名称 |
| query_name | 字符串 | 要使用的查询名称 |
| search_query | 字符串 | 相似性搜索的查询 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数 |
| number_of_results | 整数 | 搜索返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | SupabaseVectorStore | Supabase 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Upstash
此组件创建具有搜索功能的 Upstash 向量存储。 更多信息,请参阅 Upstash 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_url | 字符串 | Upstash 索引的 URL |
| index_token | SecretString | Upstash 索引的令牌 |
| text_key | 字符串 | 记录中用作文本的键 |
| namespace | 字符串 | 索引的命名空间 |
| search_query | 字符串 | 相似性搜索的查询 |
| metadata_filter | 字符串 | 按元数据过滤文档 |
| ingest_data | 数据 | 要摄取到向量存储的数据 |
| embedding | 嵌入 | 使用的嵌入函数(可选) |
| number_of_results | 整数 | 搜索返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | UpstashVectorStore | Upstash 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Vectara
此组件创建具有搜索功能的 Vectara 向量存储。 更多信息,请参阅 Vectara 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| vectara_customer_id | 字符串 | Vectara 客户 ID |
| vectara_corpus_id | 字符串 | Vectara 语料库 ID |
| vectara_api_key | SecretString | Vectara API 密钥 |
| embedding | 嵌入 | 使用的嵌入函数(可选) |
| ingest_data | List[数据/数据] | 要摄取到向量存储的数据 |
| search_query | 字符串 | 相似性搜索的查询 |
| number_of_results | 整数 | 搜索返回的结果数量 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | VectaraVectorStore | Vectara 向量存储实例 |
| search_results | List[数据] | 相似性搜索结果 |
Vectara Search
此组件基于提供的输��入在 Vectara 向量存储中搜索文档。 更多信息,请参阅 Vectara 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| search_type | String | 搜索类型,如 "Similarity" 或 "MMR" |
| input_value | String | 搜索查询 |
| vectara_customer_id | String | Vectara 客户 ID |
| vectara_corpus_id | String | Vectara 语料库 ID |
| vectara_api_key | SecretString | Vectara API 密钥 |
| files_url | List[String] | 文件初始化的可选 URL 列表 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | List[数据] | 相似性搜索结果 |
Weaviate
此组件促进 Weaviate 向量存储设置,优化文本和文档索引和检索。 更多信息,请参阅 Weaviate 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| weaviate_url | String | 默认实例 URL |
| search_by_text | Boolean | 指示是否按文本搜索 |
| api_key | SecretString | 身份验证的可选 API 密钥 |
| index_name | String | 可选索引名称 |
| text_key | String | 默认文本提取键 |
| input | 数据 | 文档或记录 |
| embedding | 嵌入 | 使用的嵌入函数 |
| attributes | List[String] | 可选附加属性 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | WeaviateVectorStore | Weaviate 向量存储实例 |
Weaviate Search
此组件在 Weaviate 向量存储中搜索与输入相似的文档。 更多信息,请参阅 Weaviate 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| search_type | String | 搜索类型,如 "Similarity" 或 "MMR" |
| input_value | String | 搜索查询 |
| weaviate_url | String | 默认实例 URL |
| search_by_text | Boolean | 指示是否按文本搜索 |
| api_key | SecretString | 身份验证的可选 API 密钥 |
| index_name | String | 可选索引名称 |
| text_key | String | 默认文本提取键 |
| embedding | 嵌入 | 使用的嵌入函数 |
| attributes | List[String] | 可选附加属性 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | List[数据] | 相似性搜索结果 |