Blaflow 中的模型组件
模型组件使用大型语言模型生成文本。
有关参数的更多信息,请参考特定组件的文档。
在流程中使用模型组件
模型组件接收输入和提示来生成文本,生成的文本被发送到输出组件。
模型输出也可以发送到 Language 模式 l 端口,然后发送到 Parse Data 组件,在那里输出可以被解析成结构化的数据对象。
这个例子在聊天机器人流程中使用了 OpenAI 模型。更多信息,请参见基础提示流程。
AI/ML API
该组件使用 AIML API 创建 ChatOpenAI 模型实例。
更多信息,请参见 AIML 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制令牌。范围:0-128000。 |
| model_kwargs | 字典 | 模型的额外关键字参数。 |
| model_name | 字符串 | 要使用的 AIML 模型名称。选项在 AIML_CHAT_MODELS 中预定义。 |
| aiml_api_base | 字符串 | AIML API 的基础 URL。默认为 https://api.aimlapi.com。 |
| api_key | SecretString | 用于模型的 AIML API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| seed | 整数 | 控制作业的可重复性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatOpenAI 实例。 |
Amazon Bedrock
该组件使用 Amazon Bedrock LLM 生成文本。
更多信息,请参见 Amazon Bedrock 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model_id | 字符串 | 要使用的 Amazon Bedrock 模型 ID。选项包括各种模型。 |
| aws_access_key | SecretString | 用于身份验证的 AWS 访问密钥。 |
| aws_secret_key | SecretString | 用于身份验证的 AWS 密钥。 |
| credentials_profile_name | 字符串 | 要使用的 AWS 凭证配置文件名称(高级)。 |
| region_name | 字符串 | AWS 区域名称。默认值:us-east-1。 |
| model_kwargs | 字典 | 模型的额外关键字参数(高级)。 |
| endpoint_url | 字符串 | Bedrock 服务的自定义端点 URL(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatBedrock 实例。 |
Anthropic
该组件允许使用 Anthropic Chat 和 Language 模型生成文本。
更多信息,请参见 Anthropic 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制令牌。默认值:4096。 |
| model | 字符串 | 要使用的 Anthropic 模型名称。选项包括各种 Claude 3 模型。 |
| anthropic_api_key | SecretString | 用于身份验证的 Anthropic API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| anthropic_api_url | 字符串 | Anthropic API 的端点。如果未指定,默认为 https://api.anthropic.com(高级)。 |
| prefill | 字符串 | 引导模型响应的预填充文本(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatAnthropic 实例。 |
Azure OpenAI
该组件使用 Azure OpenAI LLM 生成文本。
更多信息,请参见 Azure OpenAI 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| 模式 l Name | 模型名称 | 指定用于文本生成的 Azure OpenAI 模型名称。 |
| Azure Endpoint | Azure 端点 | 您的 Azure 端点,包括资源。 |
| Deployment Name | 部署名称 | 指定部署的名称。 |
| API Version | API 版本 | 指定要使用的 Azure OpenAI API 版本。 |
| API Key | API 密钥 | 您的 Azure OpenAI API 密钥。 |
| Temperature | 温度 | 指定采样温度。默认为 0.7。 |
| Max Tokens | 最大令牌数 | 指定生成的最大令牌数。默认为 1000。 |
| Input Value | 输入值 | 指定用于文本生成的输入文本。 |
| Stream | 流式传输 | 指定是否从模型流式传输响应。默认为 False。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 AzureOpenAI 实例。 |
Cohere
该组件使用 Cohere 的语言模型生成文本。
更多信息,请参见 Cohere 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| Cohere API Key | Cohere API 密钥 | 您的 Cohere API 密钥。 |
| Max Tokens | 最大令牌数 | 指定生成的最大令牌数。默认为 256。 |
| Temperature | 温度 | 指定采样温度。默认为 0.75。 |
| Input Value | 输入值 | 指定用于文本生成的输入文本。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使�用指定参数配置的 Cohere 模型实例。 |
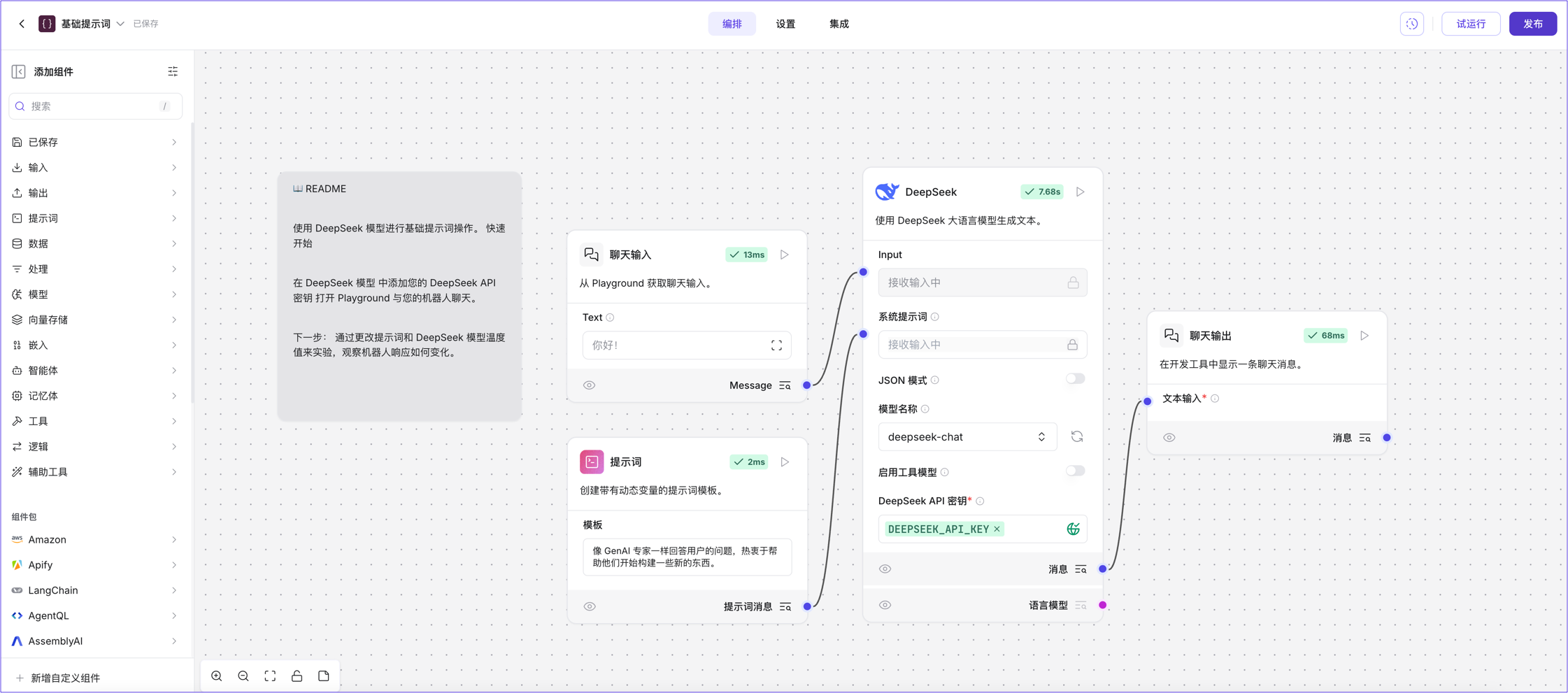
DeepSeek
该组件使用 DeepSeek 的语言模型生成文本。
更多信息,请参见 DeepSeek 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。范围:0-128000。 |
| model_kwargs | 字典 | 模型的额外关键字参数。 |
| json_mode | 布尔值 | 如果为 True,无论是否传递模式,都输出 JSON。 |
| model_name | 字符串 | 要使用的 DeepSeek 模型。默认值:deepseek-chat。 |
| api_base | 字符串 | API 请求的基础 URL。默认值:https://api.deepseek.com。 |
| api_key | SecretString | 用于身份验证的 DeepSeek API 密钥。 |
| temperature | 浮点数 | 控制响应的随机性。范围:[0.0, 2.0]。默认值:1.0。 |
| seed | 整数 | 用于随机数生成的初始化数字。使用相同的种子整数可以获得更可重复的结果,使用不同的种子数字可以获得更随机的结果。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatOpenAI 实例。 |
Google 生成式 AI
该组件使用 Google 的生成式 AI 模型生成文本。
更多信息,请参见 Google 生成式 AI 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| Google API Key | Google API 密钥 | 用于 Google Generative AI 的 Google API 密钥。 |
| 模式 l | 模型 | 要使用的模型名称,例如 "gemini-pro"。 |
| Max Output Tokens | 最大输出令牌数 | 生成的最大令牌数。 |
| Temperature | 温度 | 使用此温度进行推理。 |
| Top K | Top K | 考虑最可能的 K 个令牌集合。 |
| Top P | Top P | 采样时考虑的最大累积令牌概率。 |
| N | N | 每个提示生成的聊天完成数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatGoogleGenerativeAI 实例。 |
Groq
该组件使用 Groq 的语言模型生成文本。
- 要在流程中使用此组件,请将其作为流程中的模式 l连接,如基础提示流程所示,或者如果您使用智能体组件,则选择它作为模式 l Provider。

- 在 Groq API 密钥 字段中,粘贴您的 Groq API 密钥。 Groq 模型组件会自动获取最新模型列表。 要刷新模型列表,请点击 。
- 在 模式 l 字段中,选择要用于 LLM 的模型。 此示例使用llama-3.1-8b-instant,Groq 推荐将其用于实时对话界面。
- 在提示词组件中,输入:
_10You are a helpful assistant who supports their claims with sources.
- 点击试运行并向您的 Groq LLM 提问。 响应包括来源列表。
更多信息,请参见Groq 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| groq_api_key | SecretString | Groq API 的 API 密钥。 |
| groq_api_base | 字符串 | API 请求的基础 URL 路径。默认值:https://api.groq.com。 |
| max_tokens | 整数 | 生成的最大令牌数。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.1。 |
| n | 整数 | 每个提示生成的聊天完成数量。 |
| model_name | 字符串 | 要使用的 Groq 模型名称。选项从 Groq API 动态获取。 |
| tool_mode_enabled | 布尔值 | 如果启用,组件仅显示适用于工具的模型。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatGroq 实例。 |
Hugging Face API
该组件向 Hugging Face API 发送�请求,使用 模式 l ID 字段中指定的模型生成文本。
Hugging Face API 是用于托管在 Hugging Face 上的模型的托管推理 API,需要Hugging Face API 令牌 进行身份验证。
在这个基于基础提示流程的示例中,Hugging Face API 模型组件替换了 Open AI 模型。通过选择不同的托管模型,您可以看到不同模型如何返回不同的结果。
-
创建基础提示流程。
-
用 Hugging Face API 模型组件替换 OpenAI 模型组件。
-
在 Hugging Face API 组件中,将您的 Hugging Face API 令牌添加到 API Token 字段。
-
打开试运行并向模型提问,查看其响应。
-
尝试不同的模型,看看它们的表现有何不同。
更多信息,请参见 Hugging Face 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model_id | 字符串 | Hugging Face Hub 上的模型 ID。例如:"gpt2"、"facebook/bart-large"。 |
| huggingfacehub_api_token | SecretString | 用于身份验证的 Hugging Face API 令牌。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.7。 |
| max_new_tokens | 整数 | 生成的最大新令牌数。默认值:512。 |
| top_p | 浮点数 | 核采样参数。范围:[0.0, 1.0]。默认值:0.95。 |
| top_k | 整数 | Top-k 采样参数。默认值:50。 |
| model_kwargs | 字典 | 传递给模型的其他关键字参数。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | 语言模式 l | 使用指定参数配置的 HuggingFaceHub 实例。 |
IBM watsonx.ai
该组件使用 IBM watsonx.ai 基础模型生成文本。
要在流程中使用 IBM watsonx.ai 模型组件,请用 IBM watsonx.ai 组件替换模型组件。
示例流程如下:
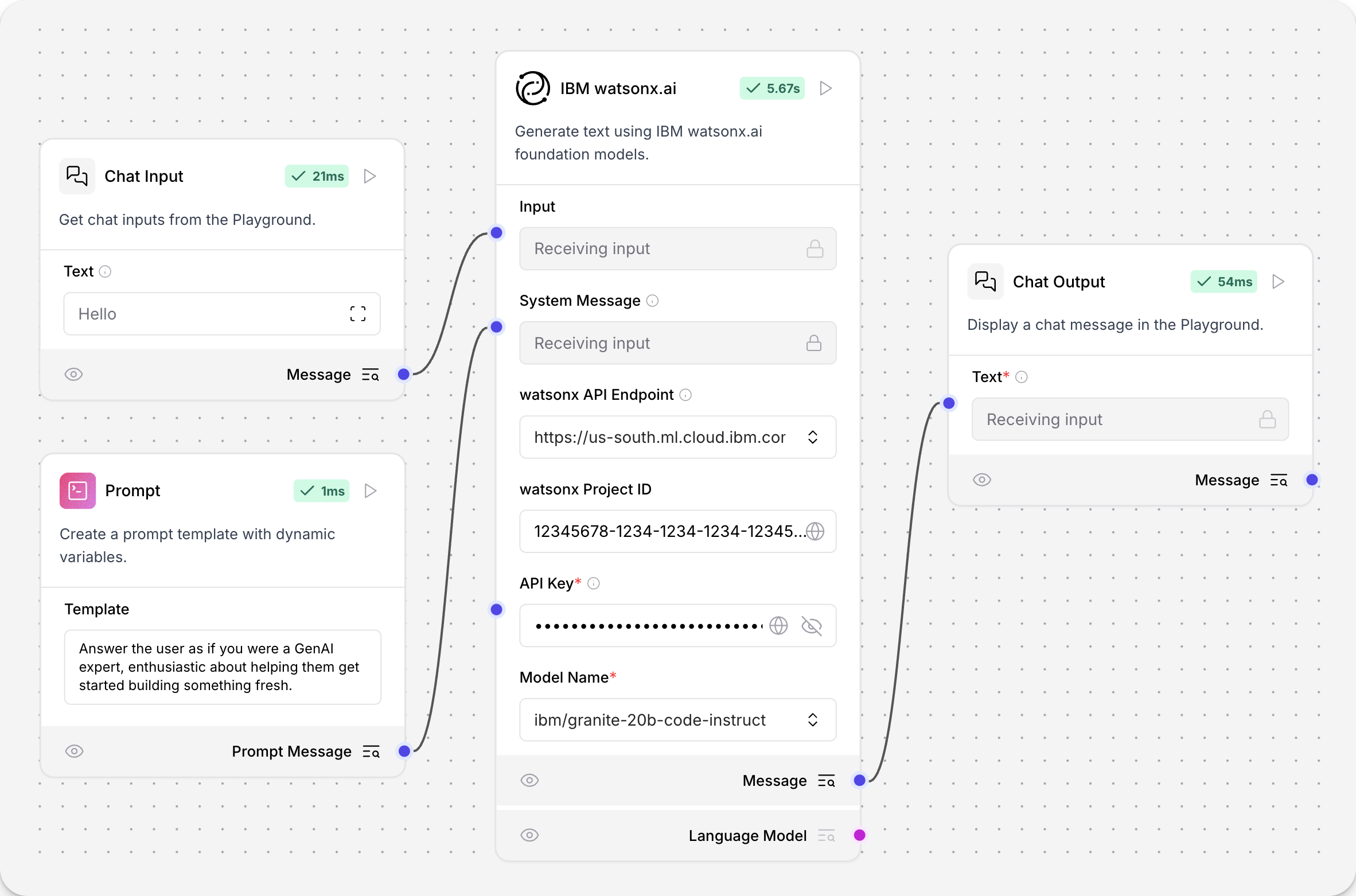
API endpoint、Project ID、API key 和 模式 l Name 的值可在您的 IBM watsonx.ai 部署中找到。 更多信息请参见 Langchain 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| url | 字符串 | watsonx API 的基础 URL。 |
| project_id | 字符串 | 您的 watsonx 项目 ID。 |
| api_key | SecretString | 您的 IBM watsonx API 密钥。 |
| model_name | 字符串 | 要使用的 watsonx 模型名称。选项由 API 动态获取。 |
| max_tokens | 整数 | 生成的最大令牌数。默认值:1000。 |
| stop_sequence | 字符串 | 生成时应停止的序列。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| top_p | 浮点数 | 控制核采样,限制模型输出概率低于 top_p 的令牌。默认值:0.9。 |
| frequency_penalty | 浮点数 | 控制重复惩罚。正值降低重复概率,负值增加重复概率。默认值:0.5。 |
| presence_penalty | 浮点数 | 控制新主题引入的概率。正值增加新主题概率。默认值:0.3。 |
| seed | 整数 | 模型的随机种子。默认值:8。 |
| logprobs | 布尔值 | 是否返回输出令牌的对数概率。默认值:True。 |
| top_logprobs | 整数 | 每个位置返回最可能的令牌数量。默认值:3。 |
| logit_bias | 字符串 | 需要偏置或抑制的令牌 ID 的 JSON 字符串。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatWatsonx 实例。 |
语言模型
该组件可使用 OpenAI 或 Anthropic 语言模型生成文本。
可作为 LLM 模型的替代组件,在不同模型提供商和模型间切换。
无需更换模型组件,只需在此组件中切换提供商下拉菜单即可切换 OpenAI 和 Anthropic,便于对比和实验。
更多信息请参见 OpenAI 文档 和 Anthropic 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| provider | 字符串 | 要使用的模型提供商。选项:"OpenAI"、"Anthropic"。默认:"OpenAI"。 |
| model_name | 字符串 | 要使用的模型名称,选项取决于所选提供商。 |
| api_key | SecretString | 用于所选提供商身份验证的 API 密钥。 |
| input_value | 字符串 | 发送给模型的输入文本。 |
| system_message | 字符串 | 用于设定助手行为的系统消息(高级)。 |
| stream | 布尔值 | 是否流式返回响应。默认值:False(高级)。 |
| temperature | 浮点数 | 控制响应的随机性。范围:[0.0, 1.0]。默认值:0.1(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatOpenAI 或 ChatAnthropic 实例。 |
LMStudio
该组件使用 LM Studio 的本地语言模型生成文本。
更多信息请参见 LM Studio 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| base_url | 字符串 | LM Studio 运行的 URL。默认值:"http://localhost:1234"。 |
| max_tokens | 整数 | 响应中生成的最大令牌数。默认值:512。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 2.0]。默认值:0.7。 |
| top_p | 浮点数 | 通过核采样控制多样性。范围:[0.0, 1.0]。默认值:1.0。 |
| stop | 字符串列表 | 遇到列表中的字符串时停止生成(高级)。 |
| stream | 布尔值 | 是否流式返回响应。默认值:False。 |
| presence_penalty | 浮点数 | 惩罚重复令牌。范围:[-2.0, 2.0]。默认值:0.0。 |
| frequency_penalty | 浮��点数 | 惩罚高频令牌。范围:[-2.0, 2.0]。默认值:0.0。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 LMStudio 实例。 |
Maritalk
该组件使用 Maritalk LLM 生成文本。
更多信息请参见 Maritalk 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。默认值:512。 |
| model_name | 字符串 | 要使用的 Maritalk 模型名称。选项:sabia-2-small、sabia-2-medium。默认:sabia-2-small。 |
| api_key | SecretString | 用于身份验证的 Maritalk API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.5。 |
| endpoint_url | 字符串 | Maritalk API 端点。默认值:https://api.maritalk.com。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatMaritalk 实例。 |
Mistral
该组件使用 MistralAI LLM 生成文本。
更多信息请参见 Mistral AI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制(高级)。 |
| model_name | 字符串 | 要使用的 Mistral AI 模型名称。选项包括 open-mixtral-8x7b、open-mixtral-8x22b、mistral-small-latest、mistral-medium-latest、mistral-large-latest、codestral-latest。默认:codestral-latest。 |
| mistral_api_base | 字符串 | Mistral API 的基础 URL。默认值:https://api.mistral.ai/v1(高级)。 |
| api_key | SecretString | 用于身份验证的 Mistral API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.5。 |
| max_retries | 整数 | API 调用的最大重试次数。默认值:5(高级)。 |
| timeout | 整数 | API 调用的超时时间(秒)。默认值:60(高级)。 |
| max_concurrent_requests | 整数 | 最大并发 API 请求�数。默认值:3(高级)。 |
| top_p | 浮点数 | 核采样参数。默认值:1(高级)。 |
| random_seed | 整数 | 随机数生成的种子。默认值:1(高级)。 |
| safe_mode | 布尔值 | 启用安全模式生成内容(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatMistralAI 实例。 |
Novita AI
该组件使用 Novita AI 的语言模型生成文本。
更多信息请参见 Novita AI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| api_key | SecretString | 您的 Novita AI API 密钥。 |
| model | 字符串 | 要使用的 Novita AI 模型 ID。 |
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.7。 |
| top_p | 浮点数 | 控制核采样。范围:[0.0, 1.0]。默认值:1.0。 |
| frequency_penalty | 浮点数 | 控制频率惩罚。范围:[0.0, 2.0]。默认值:0.0。 |
| presence_penalty | 浮点数 | 控制出现惩罚。范围:[0.0, 2.0]。默认值:0.0。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 Novita AI 模型实例。 |
NVIDIA
该组件使用 NVIDIA LLM 生成文本。
更多信息请参见 NVIDIA AI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制(高级)。 |
| model_name | 字符串 | 要使用的 NVIDIA 模型名称。默认:mistralai/mixtral-8x7b-instruct-v0.1。 |
| base_url | 字符串 | NVIDIA API 的基础 URL。默认:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 用于身份验证的 NVIDIA API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| seed | 整数 | 控制作业可复现性的种子(高级)�。默认值:1。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatNVIDIA 实例。 |
Ollama
该组件使用 Ollama 的语言模型生成文本。
更多信息请参见 Ollama 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| Base URL | Base URL | Ollama API 的端点。 |
| 模式 l Name | 模式 l Name | 要使用的模型名称。 |
| Temperature | Temperature | 控制模型响应的创造性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 Ollama 模型实例。 |
OpenAI
该组件使用 OpenAI 的语言模型生成文本。
更多信息请参见 OpenAI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| api_key | SecretString | 您的 OpenAI API 密钥。 |
| model | 字符串 | 要使用的 OpenAI 模型名称。选项包括 "gpt-3.5-turbo" 和 "gpt-4"。 |
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.7。 |
| top_p | 浮点数 | 控制核采样。范围:[0.0, 1.0]。默认值:1.0。 |
| frequency_penalty | 浮点数 | 控制频率惩罚。范围:[0.0, 2.0]。默认值:0.0。 |
| presence_penalty | 浮点数 | 控制出现惩罚。范围:[0.0, 2.0]。默认值:0.0。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 OpenAI 模型实例。 |
OpenRouter
该组件使用 OpenRouter 的统一 API 生成多种 AI 模型的文本。
更多信息请参见 OpenRouter 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| api_key | SecretString | 用于身份验证的 OpenRouter API 密钥。 |
| site_url | 字符串 | 用于 OpenRouter 排名的站点 URL(高级)。 |
| app_name | 字符串 | 用于 OpenRouter 排名的应用名称(高级)。 |
| provider | 字符串 | 要使用的 AI 模型提供商。 |
| model_name | 字符串 | 用于聊天补全的具体模型名称。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 2.0]。默认值:0.7。 |
| max_tokens | 整数 | 生成的最大令牌数(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatOpenAI 实例。 |
Perplexity
该组件使用 Perplexity 的语言模型生成文本。
更多信息请参见 Perplexity 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model_name | 字符串 | 要使用的 Perplexity 模型名称。选项包括多种 Llama 3.1 模型。 |
| max_output_tokens | 整数 | 生成的最大令牌数。 |
| api_key | SecretString | 用于身份验证的 Perplexity API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.75。 |
| top_p | 浮点数 | 采样时考虑的最大累积令牌概率(高级)。 |
| n | 整数 | 每个提示生成的聊天补全数量(高级)。 |
| top_k | 整数 | top-k 采样时考虑的令牌数量,必须为正数(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatPerplexity 实例。 |
Qianfan
该组件使用千帆的语言模型生成文本。
更多信息请参见 Qianfan 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| api_key | SecretString | 用于身份验证的千帆 API 密钥。 |
| model_name | 字符串 | 要使用的千帆模型名称。 |
| max_tokens | �整数 | 生成的最大令牌数。 |
| temperature | 浮点数 | 控制输出的随机性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的千帆模型实例。 |
SambaNova
该组件使用 SambaNova LLM 生成文本。
更多信息请参见 Sambanova Cloud 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| sambanova_url | 字符串 | API 请求的基础 URL 路径。默认值:https://api.sambanova.ai/v1/chat/completions。 |
| sambanova_api_key | SecretString | 用于身份验证的 SambaNova API 密钥。 |
| model_name | 字符串 | 要使用的 SambaNova 模型名称。选项包括多种 Llama 模型。 |
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 1.0]。默认值:0.07。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 SambaNova 模型实例。 |
VertexAI
该组件使用 Vertex AI LLM 生成文本。
更多信息请参见 Google Vertex AI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| credentials | 文件 | JSON 凭证文件。如留空则回退到环境变量。文件类型:JSON。 |
| model_name | 字符串 | 要使用的 Vertex AI 模型名称。默认:"gemini-1.5-pro"。 |
| project | 字符串 | 项目 ID(高级)。 |
| location | 字符串 | Vertex AI API 的区域。默认:"us-central1"(高级)。 |
| max_output_tokens | 整数 | 生成的最大令牌数(高级)。 |
| max_retries | 整数 | API 调用的最大重试次数。默认值:1(高级)。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.0。 |
| top_k | 整数 | top-k 过滤时保留的最高概率词汇数量(高级)。 |
| top_p | 浮点数 | 核采样时保留的最高概率词汇累计概率。默认值:0.95(高级)。 |
| verbose | 布尔值 | 是否打印详细输出。默认值:False(高级)。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatVertexAI 实例。 |
xAI
该组件使用 xAI(如 Grok)模型生成文本。
更多信息请参见 xAI 文档。
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | 整数 | 生成的最大令牌数。设置为 0 表示无限制。范围:0-128000。 |
| model_kwargs | 字典 | 传递给模型的其他关键字参数。 |
| json_mode | 布尔值 | 如果为 True,无论是否传递模式,都输出 JSON。 |
| model_name | 字符串 | 要使用的 xAI 模型名称。默认值:grok-2-latest。 |
| base_url | 字符串 | API 请求的基础 URL。默认值:https://api.x.ai/v1。 |
| api_key | SecretString | 用于身份验证的 xAI API 密钥。 |
| temperature | 浮点数 | 控制输出的随机性。范围:[0.0, 2.0]。默认值:0.1。 |
| seed | 整数 | 控制作业可复现性的种子。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| model | Language 模式 l | 使用指定参数配置的 ChatOpenAI 实例。 |