嵌入模型将文本转换为数值向量。这些嵌入捕捉输入文本的语义含义,使 LLM 能够理解上下文。
有关参数的更多信息,请参阅特定组件的文档。
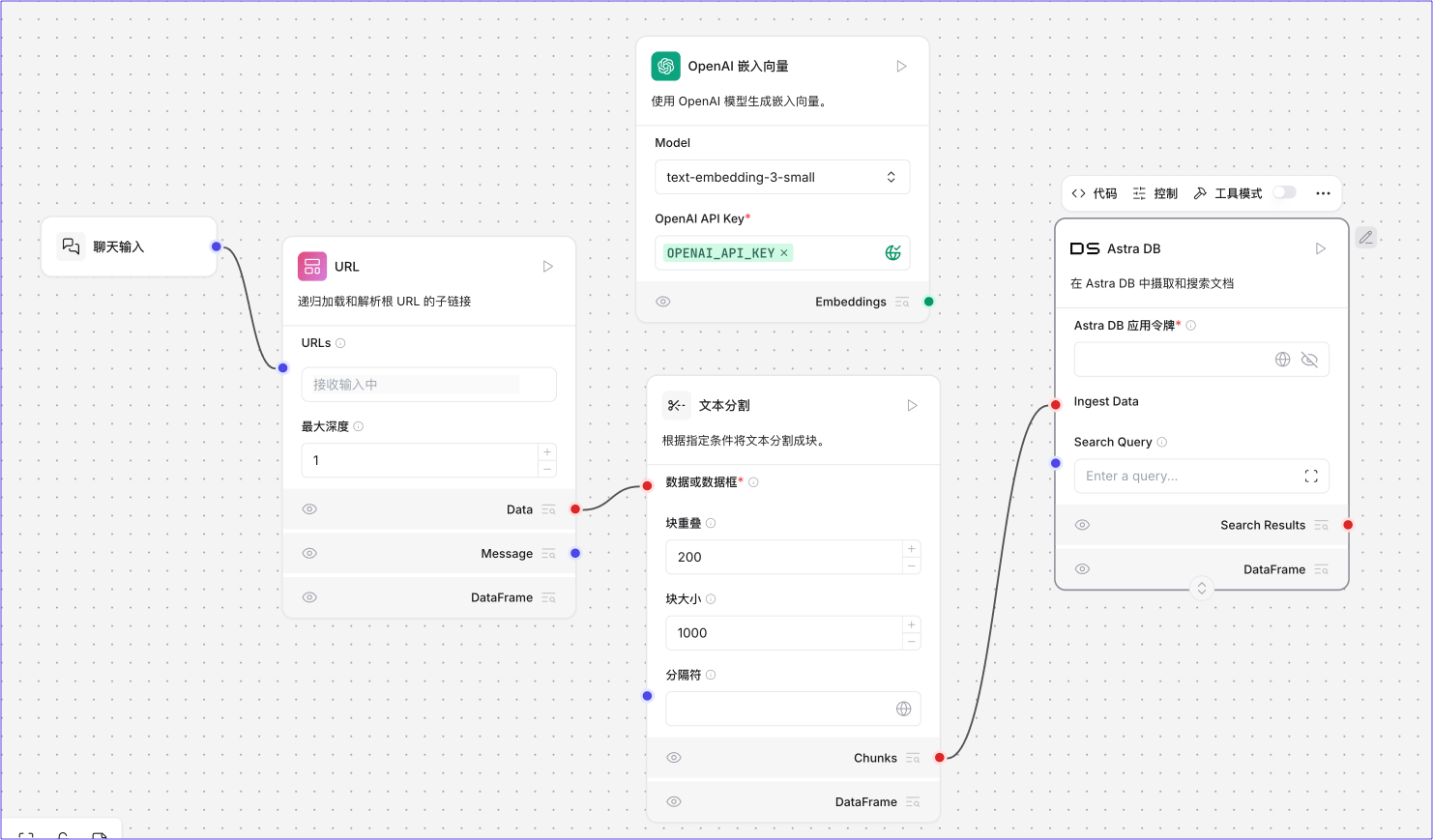
在这个文档摄取管道的示例中,OpenAI嵌入模型连接到向量数据库。该组件将文本块转换为向量并存储在向量数据库中。向量化数据可用于通知 AI 工作负载,如聊天机器人、相似性搜索和智能体。
此嵌入组件使用 OpenAI API 密钥进行身份验证。有关身份验证的更多信息,请参阅特定嵌入组件的文档。
此组件使用AI/ML API生成嵌入。
| 名称 | 类型 | 描述 |
|---|
| model_name | 字符串 | 要使用的 AI/ML 嵌入模型名称 |
| aiml_api_key | 秘密字符串 | 用于与 AI/ML 服务进行身份验证的 API 密钥 |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 用于生成嵌入的 AIML 嵌入 Impl 实例 |
此组件用于从Amazon Bedrock加载嵌入模型。
| 名称 | 类型 | 描述 |
|---|
| credentials_profile_name | 字符串 | /.aws/credentials 或/.aws/config 中具有访问密钥或角色信息的 AWS 凭据配置文件名称 |
| model_id | 字符串 | 要调用的模型 ID,例如amazon.titan-embed-text-v1。这等同于list-foundation-models API 中的modelId属性 |
| endpoint_url | 字符串 | 设置特定服务端点的 URL,而非默认的 AWS 端点 |
| region_name | 字符串 | 要使用的 AWS 区域,例如us-west-2。如果未提供,则回退到AWS_DEFAULT_REGION环境变量或~/.aws/config 中指定的区域 |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 Amazon Bedrock 生成嵌入的实例 |
将此组件连接到Astra DB 向量存储组件的嵌入端口以生成嵌入。
此组件要求您的 Astra DB 数据库具有使用向量化嵌入提供程序集成的集合。
有关更多信息和说明,请参阅嵌入生成。
| 名称 | 显示名称 | 信息 |
|---|
| provider | 嵌入提供程序 | 要使用的嵌入提供程序 |
| model_name | 模型名称 | 要使用的嵌入模型 |
| authentication | 身份验证 | Astra 中存储向量化嵌入提供程序凭据的 API 密钥名称。(如果使用Astra 托管的嵌入提供程序,则不需要。) |
| provider_api_key | 提供程序 API 密钥 | 作为authentication的替代方案,直接提供您的嵌入提供程序凭据。 |
| model_parameters | 模型参数 | 额外的模型参数 |
| 名称 | 类型 | 描述 |
| ---------- | ---- | ------------------------------- | --- | --- |
| embeddings | 嵌入 | 使用 Astra 向量化生成嵌入的实例 | | |
此组件使用 Azure OpenAI 模型生成嵌入。
| 名称 | 类型 | 描述 |
|---|
| 模式 l | 字符串 | 要使用的模型名称(默认:text-embedding-3-small) |
| Azure Endpoint | 字符串 | 您的 Azure 端点,包括资源。示例:https://example-resource.azure.openai.com/ |
| Deployment Name | 字符串 | 部署名称 |
| API Version | 字符串 | 要使用的 API 版本,选项包括各种日期 |
| API Key | 字符串 | 访问 Azure OpenAI 服务的 API 密钥 |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 Azure OpenAI 生成嵌入的实例 |
此组件使用Cloudflare Workers AI 模型生成嵌入。
| 名称 | 显示名称 | 信息 |
|---|
| account_id | Cloudflare 账户 ID | 查找您的 Cloudflare 账户 ID |
| api_token | Cloudflare API 令牌 | 创建 API 令牌 |
| model_name | 模型名称 | 支持的模型列表 |
| strip_new_lines | 去除换行符 | 是否从输入文本中去除换行符 |
| batch_size | 批量大小 | 每批中要嵌入的文本数量 |
| api_base_url | Cloudflare API 基础 URL | Cloudflare API 的基础 URL |
| headers | 请求头 | 额外的请求头 |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入 | 使用 Cloudflare Workers 生成嵌入的实例 |
此组件用于从Cohere加载嵌入模型。
| 名称 | 类型 | 描述 |
|---|
| cohere_api_key | 字符串 | 与 Cohere 服务进行身份验证所需的 API 密钥 |
| model | 字符串 | 用于嵌入文本文档和执行查询的语言模型(默认:embed-english-v2.0) |
| truncate | 布尔值 | 是否截断输入文本以适应模型的约束(默认:False) |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 Cohere 生成嵌入的实例 |
此组件计算两个嵌入向量之间选定形式的相似度。
| 名称 | 显示名称 | 信息 |
|---|
| embedding_vectors | 嵌入向量 | 包含要比较的两个嵌入向量的数据对象的列表。 |
| similarity_metric | 相似度度量 | 选择要使用的相似度度量。选项:"余弦相似度"、"欧几里得距离"、"曼哈顿距离"。 |
| 名称 | 显示名称 | 信息 |
|---|
| similarity_data | 相似度数据 | 包含计算的相似度分数和附加信息的数据对象。 |
此组件使用langchain-google-genai包中的 GoogleGenerativeAI 嵌入类连接到 Google 的生成式 AI 嵌入服务。
| 名称 | 显示名称 | 信息 |
|---|
| api_key | API 密钥 | 访问 Google 生成式 AI 服务的秘密 API 密钥(必需) |
| model_name | 模型名称 | 要使用的嵌入模型名称(默认:"models/text-embedding-004") |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入 | 构建的 GoogleGenerativeAI 嵌入对象 |
自 Blaflow 1.0.18 版本起,此组件已弃用。
请改用Hugging Face 嵌入推理组件。
此组件从 HuggingFace 加载嵌入模型。
使用此组件使用本地下载的 Hugging Face 模型生成嵌入。确保您有足够的计算资源来运行这些模型。
| 名称 | 显示名称 | 信息 |
|---|
| Cache Folder | 缓存文件夹 | 缓存 HuggingFace 模型的文件夹路径 |
| Encode Kwargs | 编码参数 | 编码过程的额外参数 |
| 模式 l Kwargs | 模型参数 | 模型的额外参数 |
| 模式 l Name | 模型名称 | 要使用的 HuggingFace 模型名称 |
| Multi Process | 多进程 | 是否使用多个进程 |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入 | 生成��的嵌入 |
此组件使用Hugging Face 推理 API 模型生成嵌入,并需要Hugging Face API 令牌进行身份验证。本地推理模型不需要 API 密钥。
使用此组件创建 Hugging Face 托管模型的嵌入,或连接到您自己本地托管的模型。
| 名称 | 显示名称 | 信息 |
|---|
| API Key | API 密钥 | 访问 Hugging Face 推理 API 的 API 密钥。 |
| API URL | API URL | Hugging Face 推理 API 的 URL。 |
| 模式 l Name | 模型名称 | 用于嵌入的模型名称。 |
| Cache Folder | 缓存文件夹 | 缓存 Hugging Face 模型的文件夹路径。 |
| Encode Kwargs | 编码参数 | 编码过程的额外参数。 |
| 模式 l Kwargs | 模型参数 | 模型的额外参数。 |
| Multi Process | 多进程 | 是否使用多个进程。 |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入 | 生成的�嵌入。 |
要本地运行嵌入推理,请参阅HuggingFace 文档。
要将本地 Hugging Face 模型连接到Hugging Face 嵌入推理组件并在流程中使用它,请按照以下步骤操作:
- 创建一个向量存储 RAG 流程。
在此流程中有两个嵌入模型,您可以用Hugging Face嵌入推理组件替换它们。
- 将两个OpenAI嵌入模型组件替换为Hugging Face模型组件。
- 将两个Hugging Face组件连接到Astra DB 向量存储组件的嵌入端口。
- 在Hugging Face组件中,将Inference Endpoint字段设置为本地推理模型的 URL。本地推理不需要API Key字段。
- 运行流程。本地推理模型为输入文本生成嵌入。
此组件使用LM Studio模型生成嵌入。
| 名称 | 显示名称 | 信息 |
|---|
| model | 模型 | 用于生成嵌入的 LM Studio 模型 |
| base_url | LM Studio 基础 URL | LM Studio API 的基础 URL |
| api_key | LM Studio API 密钥 | 用于与 LM Studio 进行身份验证的 API 密钥 |
| temperature | 模型温度 | 模型的温度设置 |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入 | 生成的嵌入 |
此组件使用MistralAI模型生成嵌入。
| 名称 | 类型 | 描述 |
|---|
| model | 字符串 | 要使用的 MistralAI 模型(默认:"mistral-embed") |
| mistral_api_key | 秘密字符串 | 与 MistralAI 进行身份验证的 API 密钥 |
| max_concurrent_requests | 整数 | 并发 API 请求的最大数量(默认:64) |
| max_retries | 整数 | 失败请求的最大重试尝试次数(默认:5) |
| timeout | 整数 | 请求超时时间(秒)(默认:120) |
| endpoint | 字符串 | 自定义 API 端点 URL(默认:https://api.mistral.ai/v1/) |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 用于生成嵌入的 MistralAI 嵌入实例 |
此组件使用NVIDIA 模型生成嵌入。
| 名称 | 类型 | 描述 |
|---|
| model | 字符串 | 用于嵌入的 NVIDIA 模型(例如nvidia/nv-embed-v1) |
| base_url | 字符串 | NVIDIA API 的基础 URL(默认:https://integrate.api.nvidia.com/v1) |
| nvidia_api_key | 秘密字符串 | 与 NVIDIA 服务进行身份验证的 API 密钥 |
| temperature | 浮点数 | 嵌入生成的模型温度(默认:0.1) |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 用于生成嵌入的 NVIDIA 嵌入实例 |
此组件使用Ollama 模型生成嵌入。
| 名称 | 类型 | 描述 |
|---|
| Ollama 模式 l | 字符串 | 要使用的 Ollama 模型名称(默认:llama2) |
| Ollama Base URL | 字符串 | Ollama API 的基础 URL(默认:http://localhost:11434) |
| 模式 l Temperature | 浮点数 | 模型的温度参数。调整生成嵌入中的随机性 |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 Ollama 生成嵌入的实例 |
此组件用于从OpenAI加载嵌入模型。
| 名称 | 类型 | 描述 |
|---|
| OpenAI API Key | 字符串 | 用于访问 OpenAI API 的 API 密钥 |
| Default Headers | 字典 | HTTP 请求的默认请求头 |
| Default Query | 嵌套字典 | HTTP 请求的默认查询参数 |
| Allowed Special | 列表 | 允许处理的特殊令牌(默认:[]) |
| Disallowed Special | 列表 | 不允许处理的特殊令牌(默认:["all"]) |
| Chunk Size | 整数 | 处理的块大小(默认:1000) |
| Client | 任意 | 用于发出请求的 HTTP 客户端 |
| Deployment | 字符串 | 模型的部署名称(默认:text-embedding-3-small) |
| Embedding Context Length | 整数 | 嵌入上下文长度(默认:8191) |
| Max Retries | 整数 | 失败请求的最大重试次数(默认:6) |
| 模式 l | 字符串 | 要使用的模型名称(默认:text-embedding-3-small) |
| 模式 l Kwargs | 嵌套字典 | 模型的额外关键字参数 |
| OpenAI API Base | 字符串 | OpenAI API 的基础 URL |
| OpenAI API Type | 字符串 | OpenAI API 的类型 |
| OpenAI API Version | 字符串 | OpenAI API 的版本 |
| OpenAI Organization | 字符串 | 与 API 密钥关联的组织 |
| OpenAI Proxy | 字符串 | 请求的智能体服务器 |
| Request Timeout | 浮点数 | HTTP 请求的超时时间 |
| Show Progress Bar | 布尔值 | 是否显示处理进度条(默认:False) |
| Skip Empty | 布尔值 | 是否跳过空输入(默认:False) |
| TikToken Enable | 布尔值 | 是否启用 TikToken(默认:True) |
| TikToken 模式 l Name | 字符串 | TikToken 模型的名称 |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 OpenAI 生成嵌入的实例 |
此组件使用指定的嵌入模型为给定消息生成嵌入。
| 名称 | 显示名称 | 信息 |
|---|
| embedding_model | 嵌入模型 | 用于生成嵌入的嵌入模型。 |
| message | 消息 | 要为其生成嵌入的消息。 |
| 名称 | 显示名称 | 信息 |
|---|
| embeddings | 嵌入数据 | 包含原始文本及其嵌入向量的数据对象。 |
此组件是Google Vertex AI 嵌入 API的包装器。
| 名称 | 类型 | 描述 |
|---|
| credentials | 凭据 | 要使用的默认自定义凭据 |
| location | 字符串 | 发出 API 调用时使用的默认位置(默认:us-central1) |
| max_output_tokens | 整数 | 令牌限制确定从一个提示输出的最大文本量(默认:128) |
| model_name | 字符串 | Vertex AI 大型语言模型的名称(默认:text-bison) |
| project | 字符串 | 发出 Vertex API 调用时使用的默认 GCP 项目 |
| request_parallelism | 整数 | 对 VertexAI 模型发出的请求允许的并行量(默认:5) |
| temperature | 浮点数 | 调整文本生成中的随机程度。应为非负值(默认:0) |
| top_k | 整数 | 模型如何为输出选择令牌,下一个令牌从顶部k个令牌中选择(默认:40) |
| top_p | 浮点数 | 从最可能到最不可能选择令牌,直到它们的概率总和超过顶部p值(默认:0.95) |
| tuned_model_name | 字符串 | 调优模型的名称。如果提供,则忽略model_name |
| verbose | 布尔值 | 此参数控制输出的详细程度。设置为True时,打印链的内部状态以帮助调试(默认:False) |
| 名称 | 类型 | 描述 |
|---|
| embeddings | 嵌入 | 使用 VertexAI 生成嵌入的实例 |