向量存储RAG
检索增强生成(Retrieval Augmented Generation,简称 RAG)是一种在您的数据上训练 LLM 并查询它的模式。
RAG 由向量存储支持,这是一个存储已摄取数据嵌入的向量数据库。
这实现了向量搜索,这是一种更强大且具有上下文感知的搜索。
我们选择了 Astra DB 作为此起始流程的向量数据库,但您可以使用 Blaflow 的任何向量数据库选项。
前提条件
- 运行中的 Blaflow 实例
- OpenAI API 密钥
- Astra DB 向量数据库,需要具备以下条件:
- 具有读写数据库权限的 Astra DB 应�用程序令牌
- 在Astra中创建的集合或在Astra DB组件中创建的新集合
打开 Blaflow 并开始新项目
- 在 Blaflow 仪表板中,点击新建流程。
- 选择向量存储 RAG。
- 向量存储 RAG流程已创建。
构建向量 RAG 流程
向量存储 RAG 流程由两个独立的流程组成,用于数据摄取和查询。
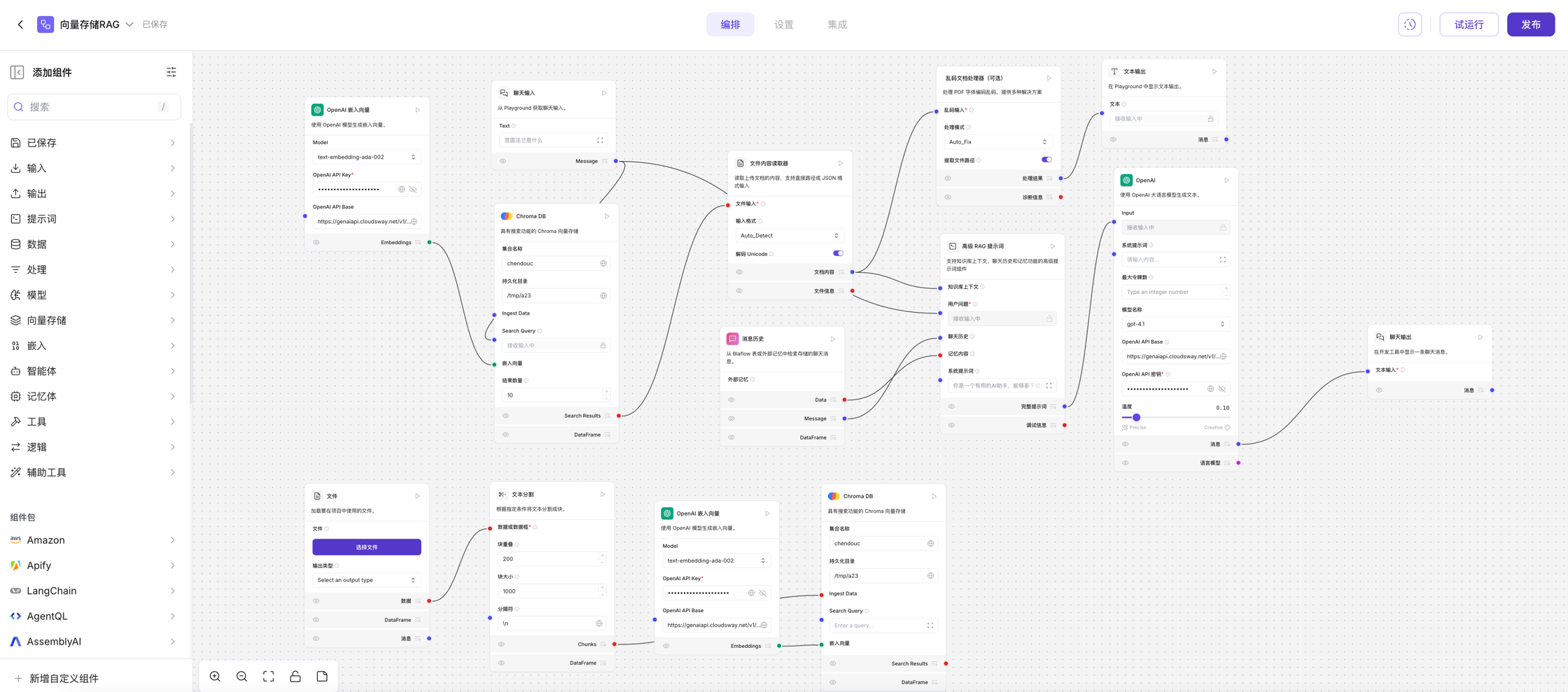
加载数据流程(屏幕底部)创建可搜索索引,用于查询上下文相似性。 此流程使用本地文件中的数据填充向量存储。 它从本地文件摄取数据,将其分割成块,在 Astra DB 中建立索引,并使用 OpenAI 嵌入模型为这些块计算嵌入。
检索流程(屏幕顶部)将用户查询嵌入为向量,这些向量与加载数据流程中的向量存储数据进行上下文相似性比较。
- 聊天输入从试运行接收用户输入。
- OpenAI 嵌入将用户查询转换为向量形式。
- Astra DB使用查询向量执行相似性搜索。
- 解析器处理检索到的数据块。
- 提示词将用户查询与相关上下文组合。
- OpenAI使用提示词生成响应。
- 聊天输出将响应返回给试运行 d。
-
配置OpenAI模型组件。
- 要为OpenAI组件创建全局变量,在OpenAI API 密钥字段中,点击 Globe按钮,然后点击添加新变量。
- 在变量名称字段中,输入
openai_api_key。 - 在值字段中,粘贴您的 OpenAI API 密钥(
sk-...)。 - 点击保存变量。
-
配置Astra DB组件。
- 在Astra DB 应用程序令牌字段中,添加您的Astra DB应用程序令牌。 组件将连接到您的数据库,并用现有数据库和集合填充菜单。
- 选择您的数据库。 如果您没有集合,选择新建数据库。 完成名称、云提供商和区域字段,然后点击创建。数据库创建需要几分钟时间。
- 选择您的集合。集合在您的 Astra DB 部署 中创建,用于存储向量数据。
info
如果您选择通过 Astra 的 vectorize 服务嵌入 Nvidia 的集合,嵌入模型端口将被移除,因为您已经使用 Nvidia 的
NV-Embed-QA模型为此集合生成了嵌入。组件从集合中获取数据,并使用相同的嵌入进行查询。
-
如果您没有集合,在组件内创建一个新集合。
-
选择新建集合。
-
完成名称、嵌入生成方法、嵌入模型和维度字段,然后点击创建。
您对嵌入生成方法和嵌入模型的选择取决于您是想使用通过 Astra 的 vectorize 服务由提供商生成的嵌入,还是由 Blaflow 中的组件生成的嵌入。
- 要使用通过 Astra 的 vectorize 服务由提供商生成的嵌入,从嵌入生成方法下拉菜单中选择模型,然后从嵌入模型下拉菜单中选择模型。
- 要使用由 Blaflow 中的组件生成的嵌入,为嵌入生成方法和嵌入模型字段选择Bring your own。在此起始项目中,嵌入方法和模型的选项是连接到Astra DB组件的OpenAI 嵌入组件。
- 维度值必须与您的集合维度匹配。如果您使用通过 Astra 的 vectorize 服务生成的嵌入,此字段不是必需的。您可以在 Astra DB 部署 的集合中找到此值。
有关更多信息,请参阅DataStax Astra DB Serverless 文档。
-
如果您使用了 Blaflow 的全局变量功能,RAG 应用程序流程组件已经配置了必要的凭据。
运行向量存储 RAG 流程
- 点击试运行按钮。在这里,您可以与使用您创建的数据库上下文的 AI 聊天。
- 输入消息并按 Enter 键。(尝试类似"你知道什么主题?"的问题)
- 机器人将用您已嵌入的数据摘要进行响应。